Split Test Node
- Atul Dattatray Bhujbal
- Neil Skilling (Deactivated)
- Austin Lohr
![]()
Purpose
The Split Test Node can accomplish several tasks:
- Randomly select a variant for A/B or multivariate testing
- Choose the winning variant that has been getting the most engagement
- Reassign the probability of selecting a variant to favor the winner
Recommended places to use this node:
- Selecting Twitter responses
- Selecting different subject lines and images for outgoing emails
- Selecting different texts and images to display on a personalized website
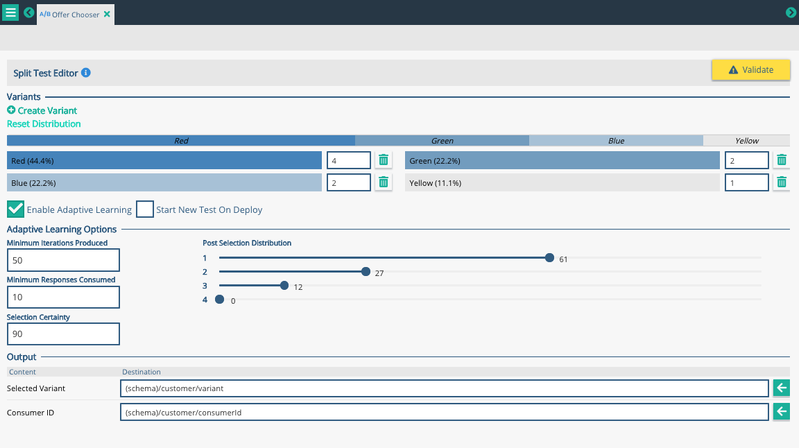
Image: A Producer split test node with four available variants, with red being the favored one.
A Split Test Node is a two-part node comprised of a 'Producer' and a 'Consumer'. There must be a Producer and a Consumer in a single project. A Producer will assign and randomly selected variant to the transaction it is processing at that time and save two outputs - 'Selected Variant' and 'Consumer ID'.

- The 'Selected Variant' is the variant that was randomly selected by the node - in the example above, it is “variant 1”
- The 'Consumer ID' is a hashed string that needs to get passed on in the process and eventually be received by a 'Consumer' node in order to see which variant is the winner. For convenience the variant name is appended to the end of the hash and each section is “split” by the underscore for easier identification.

A 'Consumer' graph will digest the Consumer ID that is generated by the 'Producer' node in order to understand which variant is the winning variant.
When implemented, the flow could look like this:
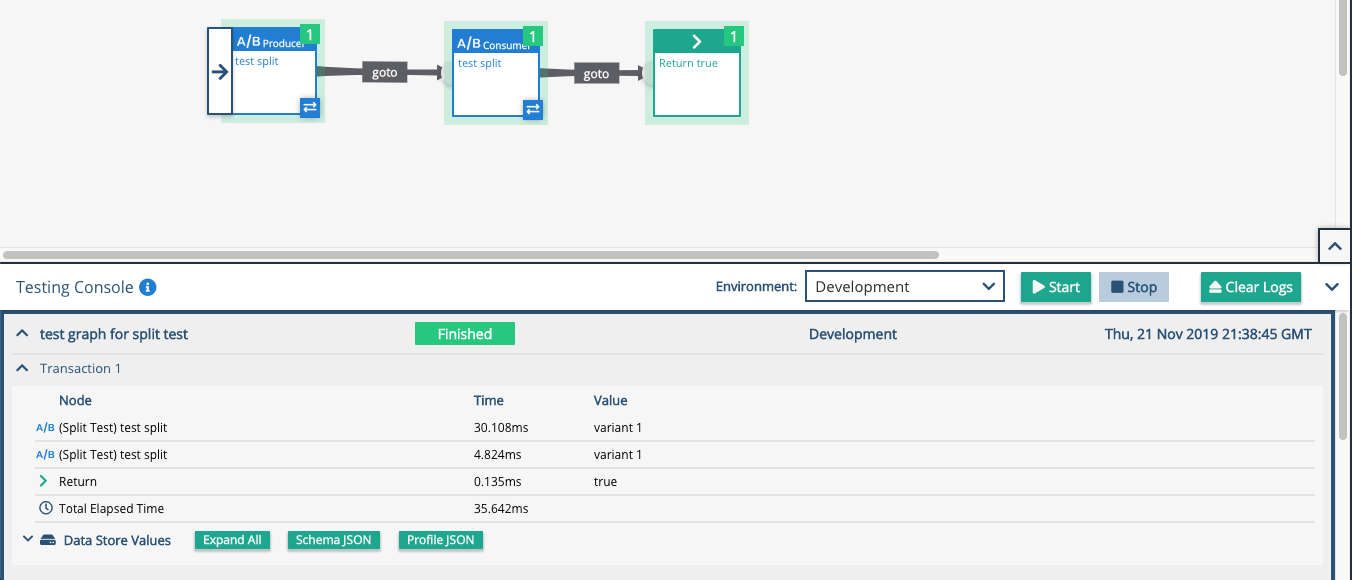
In the example above, the Consumer node is placed in the same graph but it would realistically be placed in a separate graph with the Xponent API added. As such, the flow would look like this:
Producer selects the variant and consumer ID, and sends it out to the world (email, webpage, twitter response)
User engages with the email/webpage
Xponent's API graph picks it up and the consumer node will process
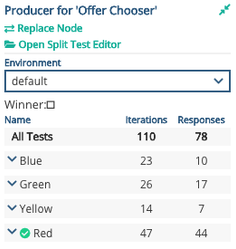
If you click on the Producer node in the graph, and look at the right panel, you will see the Producer results panel. This shows the number of iterations across all variants and the number of responses. If a winner has been chosen then it will be shown with a green tick mark.
Image: Producer results panel
Split test Options
There are 2 options that can be enabled based on the use case.
- Adaptive Learning
- New Test on Deploy
Adaptive Learning
By enabling Adaptive learning, we can change the distribution based on the winning variant, and reassign the probability of selecting a variant to favor the winner. Trials can be on-going, allowing you to select a winning variant and changing the distribution infinitely. To stop the on-going trials, you can stop the deployment for the graph. It is important to note that if you set iterations, responses, or certainty to a decimal value, you will get a notification about it being an integer, but the graph will still validate and will still function.
Image: Adaptive learning enabled
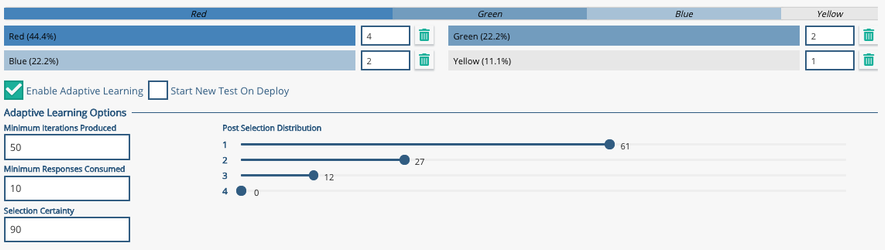
- Minimum Iterations Produced : Default value - 1000. At least 1000 transactions must be produced before variant distribution is adjusted based on adaptive learning
- Minimum Responses Consumed : Default value - 100. At least 100 responses (from the 1000 produced) must be consumed before variant distribution is adjusted based on adaptive learning
- Selection Certainty : Default value - 95. The confidence level required to select the winner. If this number is lower, the winner is decided quickly but with less confidence. The winner is chosen using a Z-Score significance test.
Post the Minimum Responses Consumed the A/B Split Test Node will select variants based on the winning ranking and the Post Selection Distribution.
Choosing a Winner
- The minimum number of iterations for an individual variant must be greater than or equal to those specified AND
- The minimum number of responses in any variant must be greater than those specified AND
- The potential winner response rate must be different from the other options by at least the confidence level given when a Z test is applied
For example, a winner will be chosen if:
- After 50 iterations AND
- After 10 responses have been consumed AND
- One of the four options has a response rate that is significantly different from the others at a 90% confidence level
Once a winner has been chosen the post selection distribution choice will then take effect - with reference to the screenshot above - 61% of the post test variants will be the winning variant, 27% will be from the second place choice and the third place will represent 12% of the selections. The fourth place variant will not be used once a winner has been chosen.
Create New Test on Deploy
On selecting this option, every time the graph is restarted or redeployed, the split test node will be reset and everything (winning variant) that was learnt so far will be reset.
Note:
It is recommended that the 'Producer' node will be placed in the process that determines the A/B group variant, while the 'Consumer' node will be placed in a different process that tracks the engagement data.
The node in a graph can be changed from Producer to Consumer by clicking on the two-way arrow attached to the node in the graph. 
The name of the existing variant cannot be edited
Producer results panel updates approximately every minute
There is no way to get the count of the iterations and responses value in the schema or public variable. Look at it on the results panel for the counts.
If an email is opened multiple times, we get multiple responses. So number of iterations can be greater than responses
Creating a Split Test
Step 1
When creating a New Item, choose the 'A/B Split Test' Node from the 'Learning category'. This will lead you to a new screen with a blank Split Test Node to configure.
Image: Configuring a blank split test node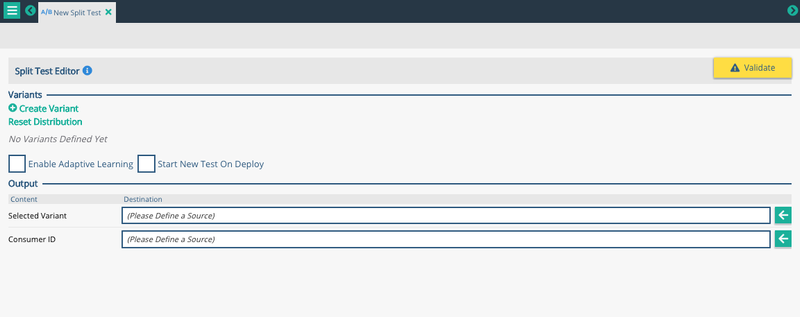
Step 2
Click 'Create Variant' at the top right corner of the screen and type the desired likelihood of selection for that variant.
![]()
If you create a variant you don't need use the trash can icon to the right of the proportion to remove it.
Step 3
Place the 'Producer' node in the process. You can select the node type to be a 'Producer' or a 'Consumer' by selecting the two-way arrow at the bottom right corner of the node.

Step 4
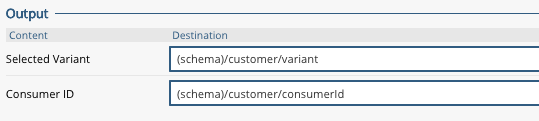
In a different process that is used to track email, tweet, or web engagement, put the 'Consumer' node in the process and configure it to digest the Consumer ID from the right field of the schema.
Validation Warnings
| Warning Text | Solution |
|---|---|---|
| Split test Meta Data must be set to a valid data reference | Ensure that the 'Selected Variant' and the 'Consumer ID' are saved to a location in the schema |
| All split tests must have at least 2 variants to be valid | Ensure that the Split Test node has at least two variants to randomly select from for the A/B testing |
| A project must have at least one consumer node per split test | Ensure that a process in the project has a Consumer node version of the Split Test node to identify a winning variant |
| A project can only have one producer node per split test | Ensure that the same Split Test node does not have two Producers in the same project |


See Also:
Related content

Privacy Policy
© 2022 CSG International, Inc.